Data preprocessing is one of the critical issues in data mining and machine learning which fills the gap between research questions and the statistical methodology for informal inferences. This includes data review, verification, cleaning and editing. In other words, data is screened to spot the missing values, validating the samples and identifying the anomalies or abnormal observations. Here, we are going to discuss about the methods for finding the abnormal (outlier) observations.
What is an outlier?
An outlier is an observation which deviates so much from the other observations as to cause the suspicions that it was generated by a different mechanism. They are treated in statistics as samples that carry high leverage.

Outliers can result from some failures in sampling mechanisms. Some outliers can be normal data and represent important information, but additional knowledge is needed to discriminate them against bad outliers. Outliers can be sometimes so obvious that they can be identified by using prior knowledge, for example they might be below or above the range considered for the variable of interest. In contrast, some outliers may not violate the physical constraints, but can cause serious model errors.
Why we need to identify outliers?
Because, if classical statistical models are blindly applied to data containing outliers, the result can be very misleading. These classical methods include estimation of mean, variance, regression, principal components, many of existing classification methods and in general all methods which involves least square estimation.
How to identify outliers?
There exist many methods which help in diagnosing the outliers, such as visualization, statistical tests, depth based or deviation based approaches. As an example, if we know that the data are generated from normal distribution, outliers are points which have very low probability that are generated from the underlying distribution.
We need to use statistical methods which are more robust to outliers present. Robust in a sense that they are less affected by outliers existing in data.
High-dimensional Outliers
Here, we will review how to spot an outlier in high dimensions and we will see how classical methods are influenced by these anomalies. Principal components are a well known method of dimension reduction, that also suggest an approach to identify high dimensional outliers. To recall, principal components are those directions that maximize the variance along each component, subject to the condition of orthogonality. Consider 1000 observation in 3-dimensional space generated from contaminated model (mixture of normals) with 0.2 contamination percentage.
As a first step, a classical principal component is run on this data.

The three axes show the direction of principal components. Out of 1000 observations, only 20% of them are coming from different normal distribution. As it can be observed, these observations totally pulled the the first principle component into their direction. This could be of no desire since it does not reveal the property of the majority of data! Now, lets run another version of principle components which is assumed to be more robust to these outliers.

Now, you can see how magically things have changed! In this graph, the first principle component is following the direction which majority of data varying in. This could help us to identify points which are potential outliers. In the following graphs, I highlighted the points which can be defined as some sort of outliers. This is possible through projecting the points into the principle component subspace. The two criteria of score distance and orthogonal distance could come in handy to diagnose these so called abnormal points. All these notions are shown in below graphs.



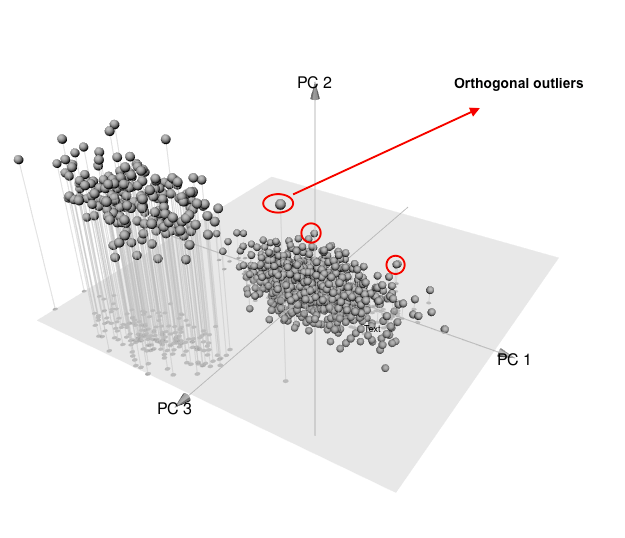

The points which have high orthogonal distance to PCA space and are remote from the center of typical data are called bad leverage points. As it has been observed these observations totally destroyed the usefulness of model.
All in all, the outliers need to be identified and investigated in order to verify their existence in the model.
require('simFrame')
require('mvtnorm')
require('rrcov')
require('pca3d')
sigma <- matrix(c(1, 0.5, 0.5,0.5,1, 0.5, 0.5, 0.5,1), 3, 3)
dc <- DataControl(size = 1000, distribution = rmvnorm, dots = list(sigma = sigma))
cc <- DCARContControl(epsilon = .2, distribution = rmvnorm, dots = list(mean = c(5, -5,5), sigma = sigma))
data<-generate(dc)
data_cont<-contaminate(data,cc)
pc<-prcomp(data_cont[,-4],center=TRUE,scale=TRUE)
Rob_pca<-PcaHubert(data_cont[,-4],scale=TRUE)
pca3d(Rob_pca@scores,show.shadows=TRUE,show.plane=TRUE)
pca3d(pc,show.shadows=TRUE,show.plane=TRUE)
No comments:
Post a Comment